Consider the following:
Problem 1:
Given a set of randomly selected
RSA numbers, estimate the portion
of numbers whose composing primes both belong to the residue class
.
Attempting to solve this apparently innocent problem will allow us
to range over a few interesting ideas from different disciplines.
It is important to first identify the constraints of the problem,
since it clearly inquires about mathematical objects whose scope
intersects with the domain of security: we shall define an RSA
number to be any odd semiprime of which we observe
neither its composing primes nor any kind of property about them.
This definition easily applies to the public key moduli of RSA
certificates, for instance.
Under this setting, the problem basically asks whether it is
possible to infer some kind of information about objects that
are kept secret; in other words, although it is generally not possible
to reconstruct the underlying factors, could we at least classify
them into well-defined categories by interacting with the observables
only? That is, given a set of ,
could one state anything at all about both and
by observing only the s?
The motivation for inquiring specifically about the residue
class of the primes is a way of restricting the domain of this hidden
information that we want to reconstruct. Also, as it will be shown, it
allows us to exploit some results from number theory to our advantage.
Let be the set of all
odd semiprimes below a given :
.
We define the following function on :
This function can be also seen as a binary relation that partitions
into the following
residue classes:
.
Indeed, since we ruled out all semiprimes multiple of
, the only possible values of the remainders
are
and .
This means that each semiprime and its respective composing primes are
congruent to any of the eight classes above, allowing us to deal with
a much smaller set than the whole .
But we can do even better by ruling out the residues
due to the following observation:
The proof is self-evident if we remember that:
So basically the residue classes where the modulo of the semiprime is
not congruent to the product of the modulo of its composing primes are
necessarily empty.
Our residue system of the semiprimes is then:
.
In the limit, one would expect roughly
equal portions of integers in the two residue classes
and
,
that is:
The two quantities differ
according to a phenomenon known as Chebyshev's bias (Kevin Ford, Jason Sneed,
Chebyshev's bias for products of two primes). The
bias generally arises when the two residue classes in the
comparison are both neither quadratic residues nor quadratic
nonresidues; indeed, is a quadratic residue
but
is not. However, the bias is much more pronounced
for the residue system of the primes, while for the semiprimes the bias
is so small that the previous identity can be replaced in practice with:
The latter espression essentially says that the semiprimes are equally
partitioned between the two residue classes, meaning that if we
pick a semiprime less than a given value, it will be congruent
to either or
with the same probability. This would preclude any
possibility of estimating which residue classes its
generating primes belong to. Indeed, if we picked for example an
,
it would either mean
,
or
but none of the two hypothesis would have even the smallest "advantage",
as the information about the residue classes of the generating primes
is lost forever due to multiplication, which could be seen as an
entropy black hole where even this one-bit of information about
and is destroyed.
There is a subtle mistake in this line of reasoning, though. The previous
result states something about a residue system of only two classes, while
the system of our investigation has four. We are implicitly assuming that,
since the semiprimes are equally partitioned between the two classes,
the composing primes are further as equally partitioned among the four
residue classes. This assumption is indeed wrong, and by computing the
actual distribution among the residue classes we convice
ourselves by experiencing at the same time a far larger phenomenon.
Let's first compute the number of odd semiprimes less
than
for each ; this sequence is known as A066265 when each of its elements is
,
the count of all semiprimes (both even and odd) less than
. Although an exact formula for the calculation of
exists,
it still requires iterating through all the primes up to the square
root of : this can require substantial time and
computational resources, and it's the main reason why A066265 stops at
and will probably not
grow much during this lifetime.
Our needs are different though: not only do we need the
exact count of the odd semiprimes at regular intervals,
but we do also need to progressively count the congruence of each
to any of the four residue classes, up to rather
than its square root. This makes the computation even more demanding
than the one involving the closed formula.
My modest means indeed allows me to obtain only the counts up to
, but this is
enough to notice the major pattern underpinning the discussion:
;(1, 3, 3): 35.294%;(3, 1, 3): 29.412%;(3, 3, 1): 18.137%;(1, 1, 1): 17.157%;204
;(1, 3, 3): 31.748%;(3, 1, 3): 30.010%;(3, 3, 1): 19.632%;(1, 1, 1): 18.609%;1956
;(1, 3, 3): 30.375%;(3, 1, 3): 29.668%;(3, 3, 1): 20.186%;(1, 1, 1): 19.770%;18245
;(1, 3, 3): 29.612%;(3, 1, 3): 29.220%;(3, 3, 1): 20.686%;(1, 1, 1): 20.482%;168497
;(1, 3, 3): 29.081%;(3, 1, 3): 28.917%;(3, 3, 1): 21.067%;(1, 1, 1): 20.935%;1555811
;(1, 3, 3): 28.732%;(3, 1, 3): 28.656%;(3, 3, 1): 21.340%;(1, 1, 1): 21.272%;14426124
;(1, 3, 3): 28.480%;(3, 1, 3): 28.446%;(3, 3, 1): 21.554%;(1, 1, 1): 21.520%;134432669
;(1, 3, 3): 28.289%;(3, 1, 3): 28.272%;(3, 3, 1): 21.727%;(1, 1, 1): 21.712%;1258822220
;(1, 3, 3): 28.136%;(3, 1, 3): 28.128%;(3, 3, 1): 21.872%;(1, 1, 1): 21.864%;11840335764
;(1, 3, 3): 28.011%;(3, 1, 3): 28.008%;(3, 3, 1): 21.992%;(1, 1, 1): 21.989%;111817881036
The last column of each row shows the count of all odd semiprimes up
to the power of in the first column. The
other columns are the percentage of each residue class. As we can
see, the classes are not at all equally apportioned! In particular,
each of the residue classes of (the
first number of each triple) is always split into one dominant class
and a minor one. Therefore, if we pick an odd semiprime less than,
say, , whose remainder
is , its generating primes
will have a higher probability to be both congruent to
than to
.
These calculations seems to confirm
another notable result in number theory (David
Dummit, Andrew Granville, and Hershy Kisilevsky, Big
biases amongst products of two primes); therein, an
asymptotic formula for the ratio between the odd semiprimes congruent to
and one quarter of the count of all odd semiprimes up to a given
guarantees the ratio to be always slightly
greater than and slowly converging to :
The attentive reader may notice that the latter
observation would very well apply to the two residue
classes and
. However, these
two classes are, in a sense, just one single opaque instance: if
one picked a semiprime that is congruent to
there would be no way to decide which among
and is congruent to
and which is congruent to , despite the
counts of the two classes differ considerably; this is due to the
commutative property of multiplication. Therefore, although the bias
affects all the four residue classes, under the setting of the
RSA numbers it gives an advantage whenever the semiprime is congruent to
.
An interesting application worth exploring would be
the "probabilistic" optimization of naive factorization algorithms like Fermat's,
by testing for candidate factors both congruent to
first.
But let's go back to our former Problem 1. We notice that
it possesses all the features of a binomial experiment: herein the
random variable models the number of semiprimes
congruent to among a
larger set of semiprimes randomly extracted
from the set of all semiprimes below a given .
There are indeed only two possible outcomes for each extraction:
either the semiprime is congruent to that class or it is congruent
to any of the remaining three. We will denote the probability of the
former outcome with , its converse is therefore
.
(Technically, since we do not reintroduce each of the extracted semiprime
back in the set, further selections are not independent since there would be
fewer semiprimes to select from; a more "accurate" distribution than the
binomial would then be the hypergeometric. However, for large populations
like that of semiprimes, we can consider the events as independent).
There a few caveats, though. One might argue that the number
of the occurrences of the congruences of interest changes as the
value of increases; this might suggest that
the Poisson-Binomial distribution is a better choice to model the
problem, since we know both empirically and from the expression
of that
slowly decreases. However, we will see that
does not change much even for large values
of , therefore we keep the calculations simple by
adopting the binomial distribution, as they could get quite
involved with the Poisson-Binomial distribution.
The probability that out of
odd semiprimes are congruent to
is therefore:
Under the assumption of the binomial model, the probability
that each semiprime is congruent
to never
changes. We might be tempted to use directly one of the values of
that we obtained empirically, however, since
the size of the semiprimes can span several
different order of magnitudes, this approach represents too much of an
approximation. Indeed, if the assumption holds that the semiprimes are
randomly selected from a larger population, they could very well lie
below, say, as well as below
.
As already mentioned, empirical calculations above
are out of question.
The solution is to estimate the parameter
of the distribution. Among the several
methods to estimate a distribution parameter, we opt for the Maximum
Likelihood Estimation: a function of called
the likelihood is generally differentiated in order to obtain
its maxima. For the binomial distribution this method yields
as the most likely estimator, that is, the proportion of positive trials. By
taking into account the expression of Dammit et al. for
we obtain:
This represents a good (under)estimation of
for large values of . Let's test its performance
with a concrete example. Let's collect all those numbers from the RSA
factoring challenge that have been factored so far; they amount to
, and the biggest of them is
in the order of . How
many of them could we expect to be congruent to
? We must interpret the
problem in the sense that the
numbers have been randomly picked from the set of all semiprimes below
where each of them
have the same probability of being congruent to
. By using our estimator
we get a
value of equal to .
We plug it into the equation of the binomial distribution for different
values of k; we compare the results with the same distribution under
the assumption that the residue class has the same probability than the
others:
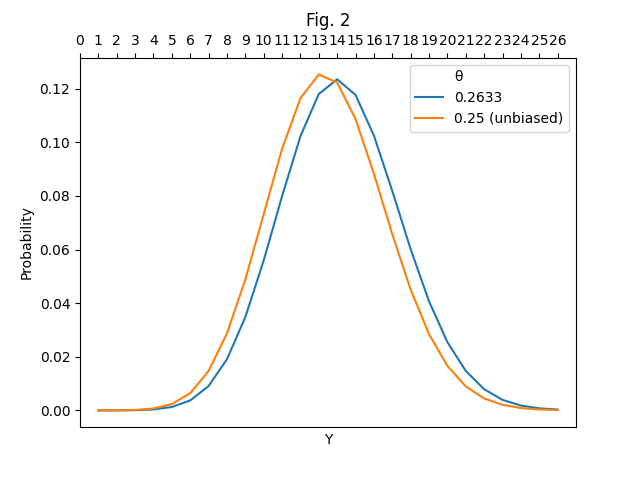
For the probability
is maximized at ,
while the unbiased "predicts"
with equal probability. Of
course, it is more revealing to calculate the probability that
the set contains at least numbers that
are congruent to the residue class: we obtain
and
under the two hypothesis, respectively. Since these
RSA numbers have been factored,
we can verify both claims. There are indeed exactly
RSA numbers in the set that are
congruent to
and only are congruent to
. Not bad.
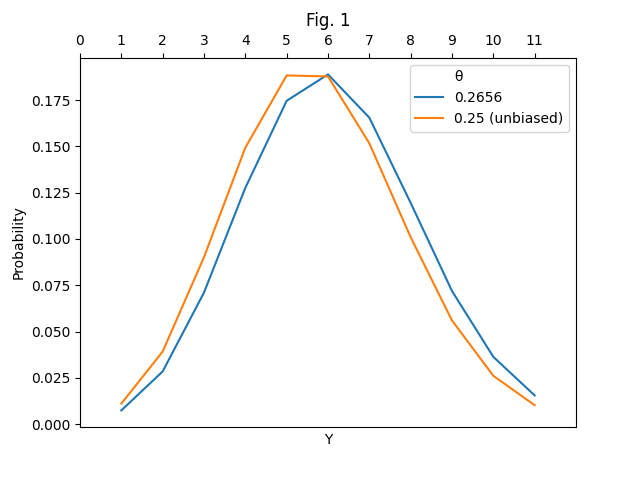
Let's finally consider the whole set of the numbers of the RSA
challenge. We have a total of
semiprimes, the majority of which have not been factored. For such large
values of , we calculate the binomial coefficient
with Stirling's approximation. The estimator obtained for values of
is ,
and the probability is maximed as per Fig 2:
We therefore estimate that the probability of having
at least
semiprimes whose composing primes are both congruent to
is .
As the factorization of the biggest RSA numbers will probably never
happen in this lifetime of ours, knowing this tiny piece of information
about their secret primes is already a victory, although it might
not help us become eligible for any cash prize.